Unlocking the Potential of Open Source AI: From Llama-3 to Business Solutions
Unlocking the Potential of Open Source AI: From Llama-3 to Business Solutions

Artificial Intelligence represents a new institution set to change the affairs of the world in much the same way as previous institutions did. Consider how our workflows have adapted to: The Wheel, Printing Press, Industrial Machinery, Electricity, The Computer, and The Internet.
Though, even with the sensational hype that is backing recent advances in the field, it can feel like access to the technology is heavyweight, risky, out of the budget, or just reserved for tech giants with billions in capital to invest in its adoption. That is, the new model Llama3 released by Meta (Formerly Facebook) was trained for 7.7 Million hours on H100-80GB GPU’s, with Amazon Web Services this would have set you back $94.63 Million.
Fortunately, you don’t need to train your own model from the ground up. You can download Meta’s Llama3 model for free and use it as a starting point to further train it on your own data. Though, for many use cases further training is unnecessary because Meta also makes available an “Instruction Tuned” version of their model that enables it to be used like a chatbot.
With a few lines of code, you can be chatting with a Large Language Model (LLM), similar to ChatGPT. With a few more lines of code the LLM can be enriched with context from your live data, enabling you to effectively chat with your data. This use case is found at the crossroads of text generation and Information retrieval. Both techniques can be further engineered to meet specific uses.
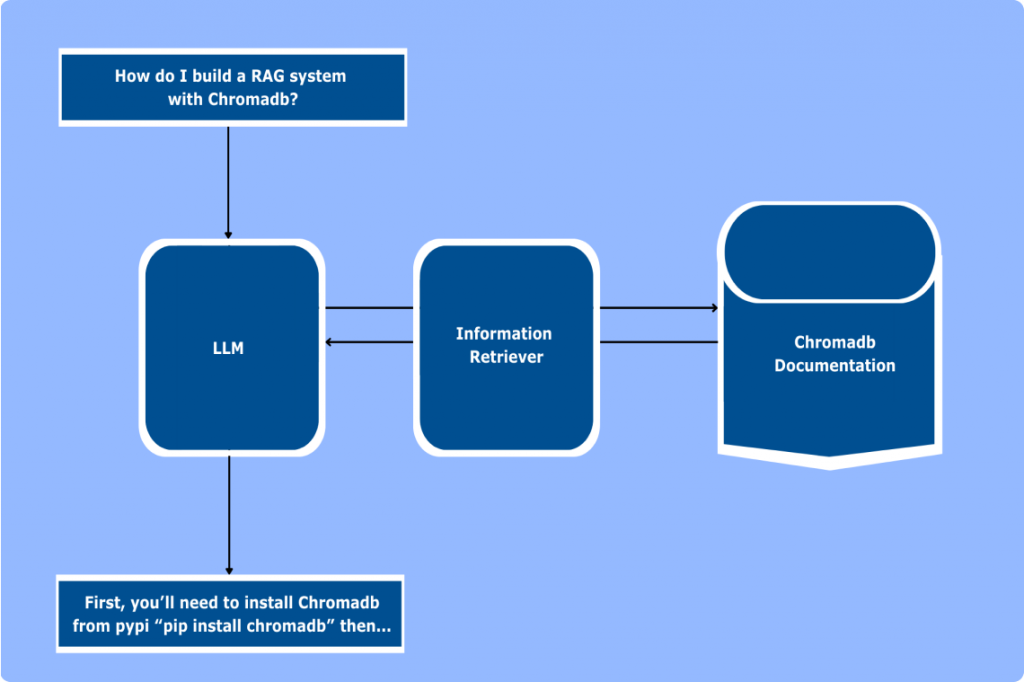
For text generation, we can choose a different model or finetune the current one. For Information Retrieval, there are many options. Including fine tuning or changing the current model, using a chatbot to assist the retrieval, and choosing a framework that can embed information retrieval methods to an SQL or Graph database such as Neo4j.
Using Llama-3 to chat with your data is one thing and it is a very popular use case, but it is just the tip of the iceberg. In fact, many such open-source models are ready to take off the shelf and can be easily directed towards business use cases. At time of writing, HuggingFace (a model repository, and framework) hosts an impressive 781,033 models. Less than a month previous, that figure was closer to 680,000.
In fact, in the time taken to write this article the figure has increased to 783,837.
These models span many, many use cases across Natural Language Processing, Machine Vision, Audio Processing, Image/Film Generation. There are also “Multi-Modal Models” which are able to combine tasks within one or more data modalities such as text, audio, and images.
At Infotel Consulting UK we know that with so many models, tasks, modalities, and uses, it can be difficult to know where to begin. Our dedicated team of artificial intelligence experts will support you on this journey to realise where AI fits into your business; growing concepts into ideas and ideas into solutions.